 >
>
"EuCanImage, un proyecto europeo para aplicar inteligencia artificial en oncología."
Lic. Naiara Mancini
Santiago Frid, investigador principal del consorcio, presenta esta iniciativa que busca construir modelos predictivos a partir de información clínica real. ¿La innovación técnica puede superar los desafíos regulatorios, operativos y de sostenibilidad?
EuCanImage es un proyecto financiado por la Unión Europea, con un consorcio formado por más de 20 instituciones de 11 países, que ambiciona cruzar inteligencia artificial y datos clínicos. Su meta específica es construir una plataforma de datos oncológicos que respete los principios FAIR (encontrables, accesibles, interoperables y reutilizables) y que permita desarrollar modelos de inteligencia artificial aplicables en escenarios reales.
El Dr. Santiago Frid, investigador principal del Hospital Clínic de Barcelona que integra el consorcio como centro proveedor de datos, presentó la iniciativa en el Simposio de Informática Oncológica organizado por el Instituto Alexander Fleming. Allí detalló la manera en que se recopilaron los datos de diversos pacientes para el desarrollo de la plataforma. A pesar de lo desafiante del componente técnico, los mayores obstáculos vinieron de otro lado: la cuestión regulatoria y la sostenibilidad económica del proyecto.
Un modelo colaborativo
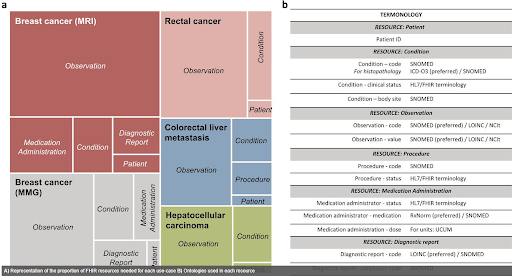
El proyecto se apoya en una infraestructura internacional que articula imágenes médicas, datos clínicos, genéticos y demográficos para alimentar modelos de inteligencia artificial aplicables a la oncología. Esta red colaborativa permite recolectar y estructurar información compleja de pacientes con cáncer de mama, colorrectal e hígado. Sin embargo, el proceso no se limitó a reunir imágenes: cada hospital tuvo que armar su propio circuito para organizar el trabajo. Primero, identificar a los pacientes que servían para el estudio en sus sistemas; después, buscar sus imágenes en los sistemas de almacenamiento médico (PACS); segmentarlas y etiquetarlas con herramientas como Collective Minds y, finalmente, la carga estructurada de estos datos clínicos en sistemas especializados como REDCap para poder usarlos después en modelos de inteligencia artificial.
De acuerdo con Frid, “para los datos clínicos, cada uno tuvo que rebuscárselas para encontrar en qué parte de la historia clínica estaban. A veces son notas clínicas, a veces son datos estructurados, y a veces hay que generarse el conocimiento de dónde está todo eso, buscarlo y hacer un proceso que se llama ETL: extraer, transformar y cargar los datos dentro de una plataforma. Si bien se usó un estándar para representar los datos, el pipeline para lograrlo es el que cada uno se tuvo que armar a su manera”.
La interoperabilidad entre instituciones se logró gracias a un esfuerzo transversal de estandarización y modelado de variables, que permite hoy contar con una base sólida de más de 15.000 casos listos para investigación y entrenamiento de modelos explicables de IA.
Legalidad e interoperabilidad
Más allá del enorme avance en el desarrollo del modelo, Santiago Frid hizo hincapié en el impacto que tuvo para el proyecto el reglamento europeo GDPR sobre el tratamiento de datos personales, advirtiendo que las diferencias en la interpretación del marco legal entre países complicaron la transferencia y vinculación de datos clínicos y radiológicos. “Uno de los principales obstáculos fue cómo se define, en la práctica, el principio de anonimización. ¿Qué datos podemos sacar del hospital y usar en un repositorio de investigación?”, detalló Santiago, y profundizó: “El consentimiento informado no es viable cuando hablamos de miles de pacientes retrospectivos, así que hay que apelar a la anonimización. Pero, ¿cómo se considera que los datos están realmente anonimizados? No es tan fácil hacer esa interpretación”.
En el terreno técnico, la elección del modelo de datos también trajo dificultades. Aunque inicialmente se propuso OMOP, un modelo muy utilizado en investigación biomédica, los evaluadores exigieron la migración a FHIR, cuyo inconveniente, según Frid, radica en que “es un estándar más orientado al uso asistencial e intercambio de datos, no tanto a la investigación. Además, tiene poca adopción en investigación oncológica: apenas un 12%”. Asimismo, esta decisión forzó al equipo a rehacer buena parte de un trabajo ya avanzado, bajo la obligación de adaptar terminologías y estructuras para este modelo.
Una respuesta estructural a un problema sistémico
A pocos meses del cierre del proyecto (tras una extensión concedida), aún persisten interrogantes sobre la sostenibilidad de los repositorios generados. Sin financiamiento garantizado para su mantenimiento, el acceso a los datos curados podría verse comprometido.
Es en este contexto donde surge EUCAIM (European Federation for Cancer Images), una nueva infraestructura europea que busca articular los esfuerzos previos y establecer estándares comunes para el modelado, almacenamiento y uso de datos oncológicos. A diferencia de EuCanImage, no está centrado en la generación de modelos de IA, sino en garantizar interoperabilidad técnica, semántica y organizacional a largo plazo. Propone una arquitectura híbrida: un hub central con datos anonimizados, y una red federada donde los datos permanecen locales, pero accesibles para análisis distribuidos.
“EUCAIM, en lugar de empezar por lo clínico (por ejemplo, preguntarse “¿puede una resonancia de mama predecir el resultado de la biopsia?”, con la idea de evitar la biopsia y determinar el tipo de cáncer solamente a partir de las imágenes), plantea otra cosa: ¿cómo construimos la infraestructura para compartir datos sin tropezar con barreras legales o técnicas, y dejamos que la pregunta clínica surja en su momento? Así, EUCAIM se creó aprovechando los aprendizajes de todos esos proyectos, pero como un paraguas mucho más grande”, puntualizó Santiago.
Reflexiones finales
La experiencia de EuCanImage expone un punto crítico para el futuro de la IA en salud: no alcanza con contar con datos ni con algoritmos poderosos. Sin modelos de datos estandarizados, sin marcos éticos viables y sin sostenibilidad económica, los avances quedan atrapados en pilotos o repositorios de difícil acceso.
El mayor reto es construir un ecosistema donde los datos oncológicos no solo se generen, sino que puedan compartirse, entenderse y aprovecharse colectivamente, sin volver a empezar desde cero cada vez.
